Generative AI tools like ChatGPT and MidJourney have caught the public’s imagination, sparking renewed interest in the potential of AI. And in the business world, we’re seeing companies in pretty much every industry trying to ride the hype wave, highlighting the role of AI if they’re already using it, or looking for ways to fold it into their products and services.
AI already plays a big role in ad tech, and the potential is certainly there for generative tools to add value. But understanding the AI opportunity also means understanding AI’s risks and limits, says Vova Kyrychenko, CTO at ad tech and martech software development business Xenoss.
Here Kyrychenko breaks down the reality behind AI’s role in ad tech: what it is, where it’s used, and why product managers should think carefully before rushing to jump on the AI bandwagon.
At first glance, AI and CTV appear set for a happy marriage. A lot of under-the-hood decision-making in CTV platforms is already handled by artificial intelligence – it automates auctions, improves the precision of targeting, analyses ad performance, and can predict how a campaign will perform based on historical data.
Generative AI, with GPT as its poster child, is also making a mark with generating or personalising ads, aiming for better conversion.
AI adoption has been riding the hype wave since the beginning of the year, and the spell is far from wearing off. From all sides of ad tech – DSPs, SSPs, CMPs, fraud prevention tools – I am seeing swaths of vendors rebranding their products/tech as “something-AI” and pushing machine learning, previously kept in the background, to be front and centre of the product.
As the CTO of a company focused on building AI/ML-enabled ad tech platforms, I have zero interest in encouraging ad tech vendors to pull the plug on AI initiatives. But I do see a strong need for a reality check about deploying AI algorithms in ad tech platforms.
Setting definitions
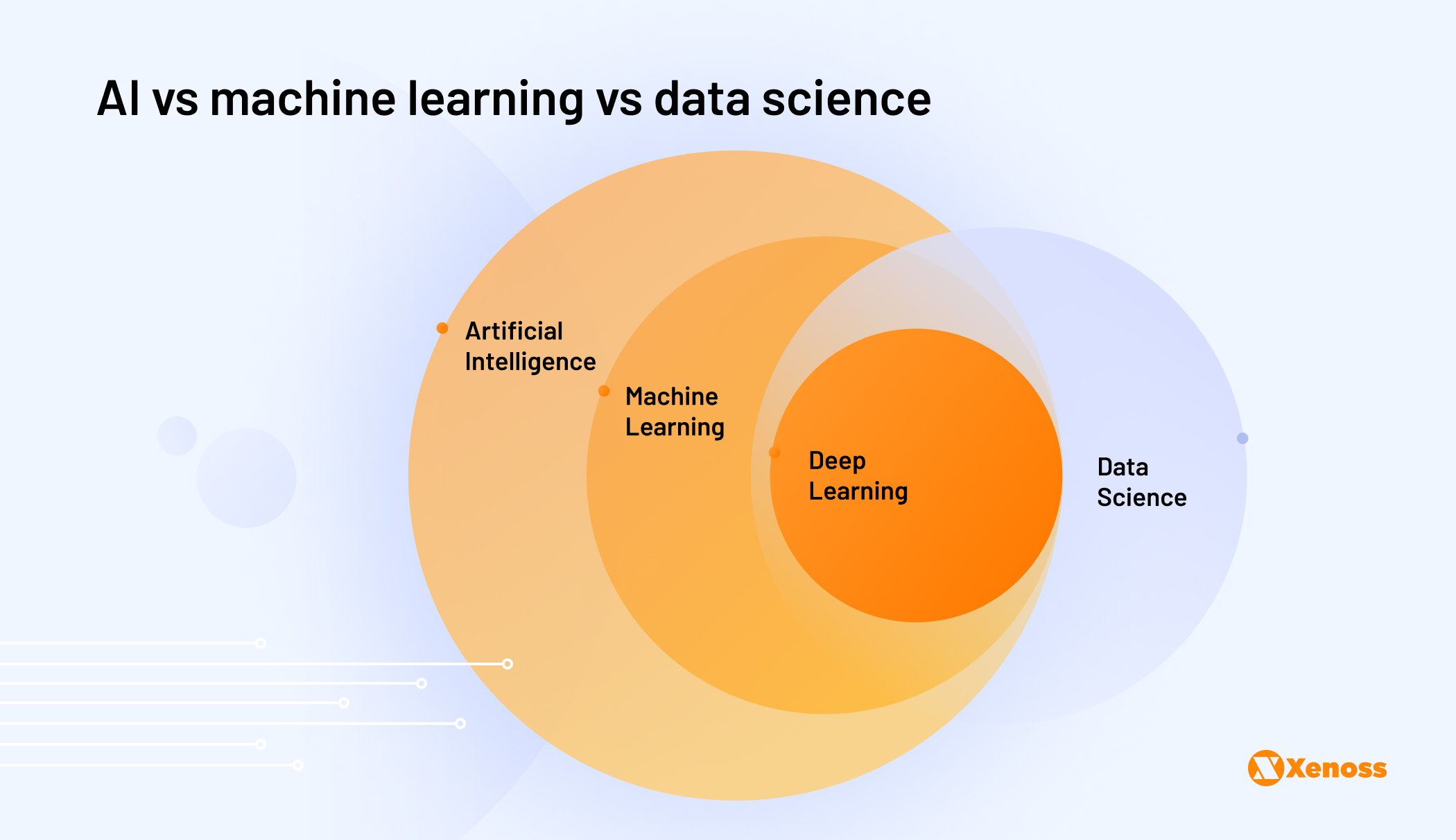
Understanding the difference between artificial intelligence and other terms which are often used interchangeably – machine learning and data science – is a good place to start.
The standard definition of artificial intelligence is the ability of a computer to perform tasks commonly associated with intelligence: reasoning, creative work, and learning from past experiences. When taken at face value, this definition might imply we have not reached artificial intelligence yet, as it’s hard to prove computers can truly reason or be creative in the broadest sense.
Thus, AI is a spectrum, with “weak” and “strong” systems on both ends.
Weak or “narrow” AI focuses on specific types of tasks – like answering questions asked by a user. It is not universal, insofar as one algorithm cannot be used both to support autonomous vehicles and generate an advertising creative.
An attempt to unravel AI’s tangled web quickly makes one realize that “artificial intelligence” is an umbrella term encompassing other tools and technologies.
At a lower level of complexity, there’s machine learning: a branch of AI focused on using historical data to train models that can generate new outputs based on a high volume of historical inputs.
In ad tech, machine learning is used more broadly than full-on AI to make real-time bidding decisions, improve targeting quality, empower recommendation engines, or detect ad fraud.
Then there’s data science, a set of techniques for collecting, filtering, and analysing data, be it the features of bid requests, auction prices, CTR rates, user data for targeting, and so on. The precision of machine learning and AI algorithms depends on the accuracy of the data used for training. If input data is not collected or filtered correctly, a machine-learning model will make inaccurate predictions.
In the last five years, machine learning models have been a growing presence in the CTV ecosystem: Nielsen used ML to predict TV ratings, and Roku’s models help connect advertisers to users who are more likely to convert, allowing advertisers to allocate budgets strategically.
Examples like these make it look like smooth sailing for machine learning’s deployment in advertising when, in reality, it’s anything but. Research from AI publication KDnuggets suggests that 80 percent of all machine learning models that are developed are never deployed. The root of the issue, backed by both statistical and anecdotal evidence, is that models get a lot more attention than use cases. We talk a lot about machine learning techniques and not enough about the end goal.
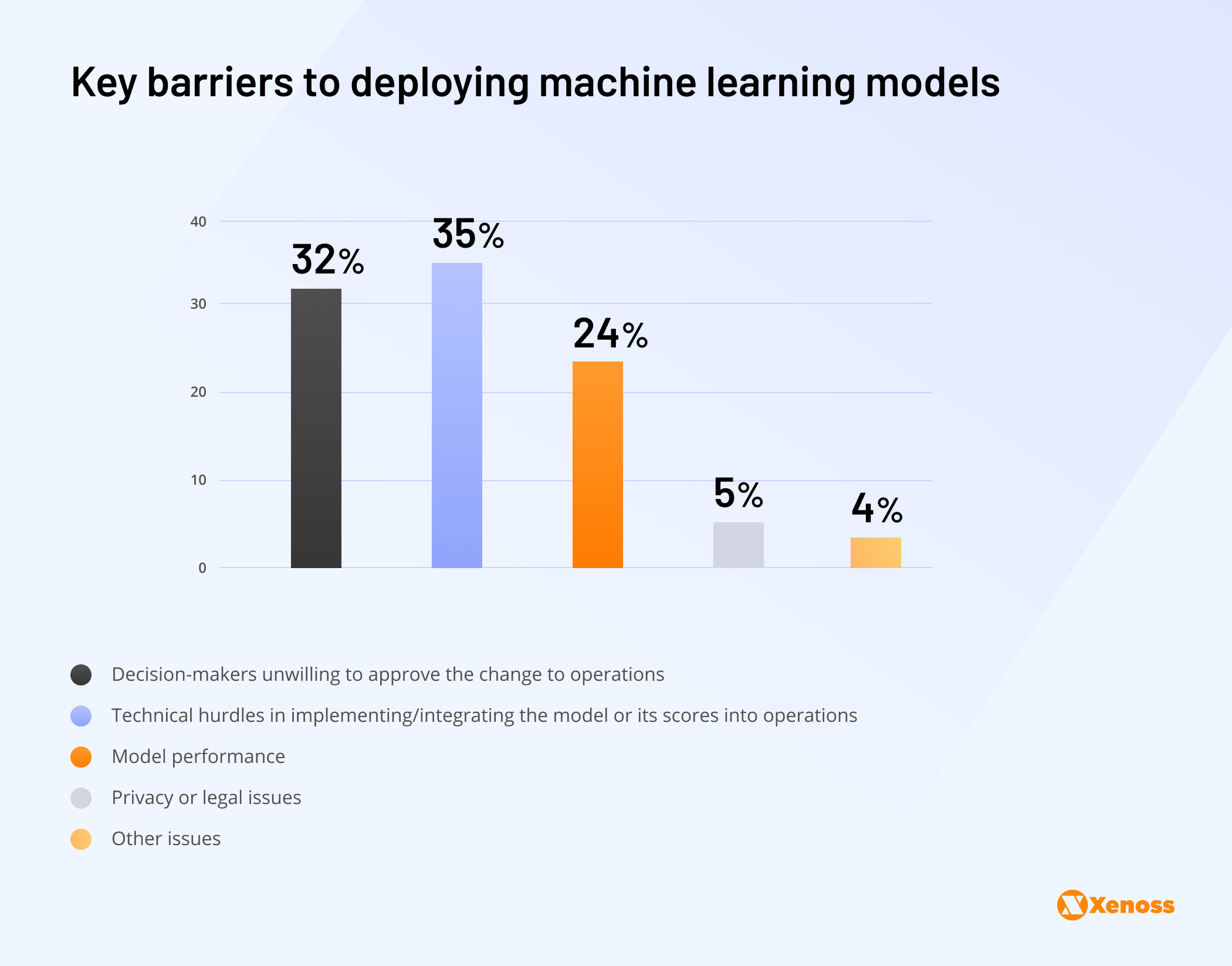
The disconnect often has to do with data scientists lacking the ad tech expertise to know how a model can optimise operations, what’s really missing in the industry, and how success should be defined.
In my experience, when teams think about AI development with a specific goal in mind, the return on investment can exceed all expectations. Our team once worked with a product team of a DSP platform that turned to AI to solve a specific problem – a lack of tools for activating user behaviour data. The implementation of machine learning was highly successful because the leadership did not put the cart before the horse and focused on the problem, not the model itself.
Teams who take a problem-first approach to development often realize that machine learning is not necessary to get the job done. There are documented cases of basic heuristics (rule-based algorithms that allow inferring a statement from a limited set of data) outperforming more complex deep learning models.
Of course, using a heuristic doesn’t have much of a ring to it, so decision-makers might push for machine learning even when there’s no need
However, to protect yourself from high-cost and low-return scenarios, consider using a heuristic for benchmarking and concept validation. If a heuristic-based algorithm is functional in an MVP, bringing it to production is often a better idea than developing a more complex machine-learning algorithm that might end up yielding lower precision.
One more thing: machine learning runs on data, so, if you don’t have a high-volume dataset, a heuristic might have higher accuracy than a full-blown model.
The wild west of AI regulation
Data regulations are another reason to consider statistical methods rather than ML tools like neural networks, especially in ad tech, where privacy lawsuits are a genuine concern. Although AI is often hailed as the answer to the industry’s data problem, zooming in on the loopholes in data privacy regulations throws up further questions.
There’s been a lot of action around limiting the use of data for training AI algorithms. Earlier this year Getty Images sued Stability AI, an AI startup, for misusing the company’s data to train an image generation platform. Reddit just rolled out a new API policy that will require developers to pay for using the platform’s data for machine learning.
Understanding the promise behind AI, those whose data is used to fuel new projects want to be fairly compensated. At the same time, for AI developers, tightening regulation is yet another hurdle to clear in an already shrinking data landscape.
Also, given the rapid growth of machine learning, it’s unsurprising that current regulations have gaps in AI/ML governance.
Let’s take a look at the EU’s General Data Protection Regulation (GDPR). GDPR offers some guidance on using data for AI development in Article 22, but following best practice to its fullest extent is somewhat challenging.
The article states that “the data subject shall have the right not to be subject to a decision based solely on automated processing, including profiling” unless it “is based on the data subject’s explicit consent”.
Article 5 puts extra pressure on AI teams to keep data “accurate and where necessary kept up to date”, adding that “initiative must be taken to address inaccuracies”.
There were many vocal opponents of the approach to AI governance presented in the GDPR. Pressure to comply with the directive minimises the amount of data companies are allowed to collect, narrows down the range of use cases for a dataset, and puts limitations on the applications of “automated decision-making”.
The consensus is that machine learning can be compliant with GDPR, but the ambiguity of compliance measures (AI is never explicitly mentioned) and lack of further guidance means it’s hard to be confident what compliance really looks like.
Then there are emerging pieces of legislation like the EU’s AI Act, proposed in 2021 though not yet passed. That law classifies AI systems into four categories: unacceptable, high risk, limited risk, and minimal risk – and it’s still unclear where AI-enabled ad tech fits within these categories.
Other governments – the UK, New Zealand, and more – are also drafting legislation (the United States Congress, at the time of writing, does not have a clear stance). Until it’s clear how strict these regulations will be, brands, publishers, and ad tech vendors are hesitant to venture into uncharted territories. It’s been reported, for example, that a fair share of BBDO clients would reject the agency’s work if generative AI was involved.
Machine learning, pocket burning: the cost conundrum of AI
Regulations, of course, are not AI’s only problem – development costs are also a major one.
It’s true that the upfront costs of AI development have gone down – these days connecting an ad tech platform to OpenAI’s API is enough to roll out an AI-powered feature with no significant training and deployment costs.
But there’s a significant caveat. OpenAI uses a pay-as-you-go subscription for GPT. It charges teams per amount of characters generated by the platform. As AI-powered solutions take off and skyrocket, maintenance costs follow suit. Such was the case with AI Dungeon, a text-based GPT-powered role-playing game: at one point, the company’s bill ballooned from $20,000 to over $50,000 in just three days.
Let’s break down what makes AI models expensive and what machine learning teams should be aware of if they decide to build a custom model instead of relying on a third-party API.
The first bottleneck is computing power: a functional machine learning model needs to run millions of calculations before it returns a response, which increases the computing power required to serve pages or web apps by a huge margin.
Hardware costs are also a deterrent to AI growth. Unfortunately, traditional processors are ill-equipped to run machine learning algorithms: they are slow and can break down altogether under the pressure of heavy computational loads.
The so-called “AI chips” used for running machine learning models are in short supply and quite expensive. Although there’s a race for AI chip dominance between NVIDIA, Intel, and AMD, costs are still very high. At the time of writing, AI chips cost $10,000 apiece (and even these can have a meltdown under high loads).
Ad tech is a race against the clock, and machine model struggles to make it on time
Latency is another hurdle ad tech vendors have to overcome if they are serious about deploying machine learning algorithms. Despite hundreds of deep learning success stories, engineers often complain about the low speed of running and training models, making it a no-go for RTB platforms (DSPs and SSPs), where predictions need to arrive almost immediately.
The challenges of low-latency algorithms stem from the complexity of tasks an ML algorithm needs to perform in this time frame: generating a prediction, processing the input, and enriching it with more data, post-processing the output, and sending it back to the caller.
Machine learning engineers need to be involved in orchestrating the process by load balancing, autoscaling the number of available gateways, and so on. The bottom line is that training neural networks in real-time requires a lot of server power, accessible to industry players like Criteo, but rarely to smaller projects.
While computer vision or predictive analytics are definitely not off-limits in ad tech projects (our team once used both to help build a creative management platform), ad tech engineers should prioritise simpler algorithms over complex models for the sake of reducing latency.
Major industry players have their ad tech AI mishaps
Even with budget, tools, and talent lined up, it’s not rare for large industry players to fail in building high-performance models. Netflix once made a miscalculation by investing over $1 million and over 2,000 working hours in an ML-enabled recommendation engine that generated only an incremental improvement (8.4 percent) over the baseline value.
A few years back, P&G had to pull their digital advertising budget after realizing that a machine learning model they used for targeting enhancement placed ads in inappropriate contexts. Jay Pattisall, VP and principal analyst at Forrester, cautioned marketers to double-check AI-generated ads in a comment for The Wall Street Journal: there’s a risk of large language models generating creatives with wrong prices and other errors.
The bottom line
Certainly, pulling the plug on AI when the entire world is getting into it is counterintuitive and is likely a strategic misstep. To draw this to a close, I’d like to echo IAB guidelines: it is important to cut through the noise, set realistic expectations, and understand the maintenance scope – talent, computing power, and resources for data updates and algorithm retests – before authorising an AI project. Besides, AI is not always the answer to a problem your product team might be facing. Keep that in mind!